
Aaron Foyer
Director, Research
What's the outlook?
Aaron Foyer
Director, Research
In September 1830, a set of iconic yellow and black passenger carriages pulled by a steam punk-styled Northumbrian locomotive left Manchester en route for Liverpool. At the time, the 35-mile trip between the two emerging industrial cities would take a horse-drawn carriage up to six hours, barring inclement weather. With the new Liverpool and Manchester Railway (L&MR), it would take just two.
The carriages on this particular journey were filled with the likes of the UK’s prime minister and the Duke of Wellington. It would go down as the maiden voyage for the world’s first passenger train.
Excitement: The line was an instant hit for passengers, who realized traveling by rail was both more comfortable and affordable than by road, leading the line to find astounding financial success. Investors took notice.
Over the following years, a fervor grew for British railways. By 1842, just over 10 years later, nearly 2,000 miles of rail had been built across Britain, roughly the distance between London and Istanbul.

Rolling stock on the Liverpool and Manchester Railway, 1831 // Wikipedia Commons
The growth led to the creation of 15 new British stock exchanges, and railroad stocks roared. In 1838, the value of railway companies made up 23% of these exchanges. By 1848, that had ballooned to 71%.
Between 1845 and 1847, at the zenith of investor hype fueled by the promise of widespread economic growth, the British Parliament approved 8,590 miles of new rail. In 1845 alone, the government greenlit 3,000 miles of new projects, as much as the previous 15 years combined.
The crash: It eventually dawned on investors that many of the approved routes were redundant with existing lines while others served regions seldom likely to be used, making them worthless. There was also the unraveling of a massive Ponzi scheme run by the “railway king,” English financier George Hudson. As a result, railroad shares tumbled 20% in a single month, a staggering rate for the time, and railway dividends fell to 2.4%, well below their peak of 7%.
The entire saga would come to be known as the UK’s Railway Mania, a lesson in what can happen when emerging technologies align with political and economic interests.
It’s hard not to see parallels between the Railway Mania and the current AI and data center frenzy.
Like railroads, AI is promised by its champions as a revolutionary technology set to usher in a new wave of industrialization and economic growth. And just as the value of railroad stock ballooned to dominate British markets, AI-related stocks now dominate the S&P500. Just eight tech stocks — Broadcom, Apple, Tesla, Microsoft, Meta, Amazon, Alphabet and Nvidia — together referred to as the BATMMAAN stocks, gained $6.2 trillion in market value last year. Combined, the other 592 companies in the index gained just half of that.
What’s at stake: Bloomberg estimates AI infrastructure, including data centers, utilities and applications, will cost over $1 trillion over the next several years to build. But that spending is not locked in. Despite both the ramp-up in construction spending and significant hype and market excitement around AI, there are reasons to be skeptical.
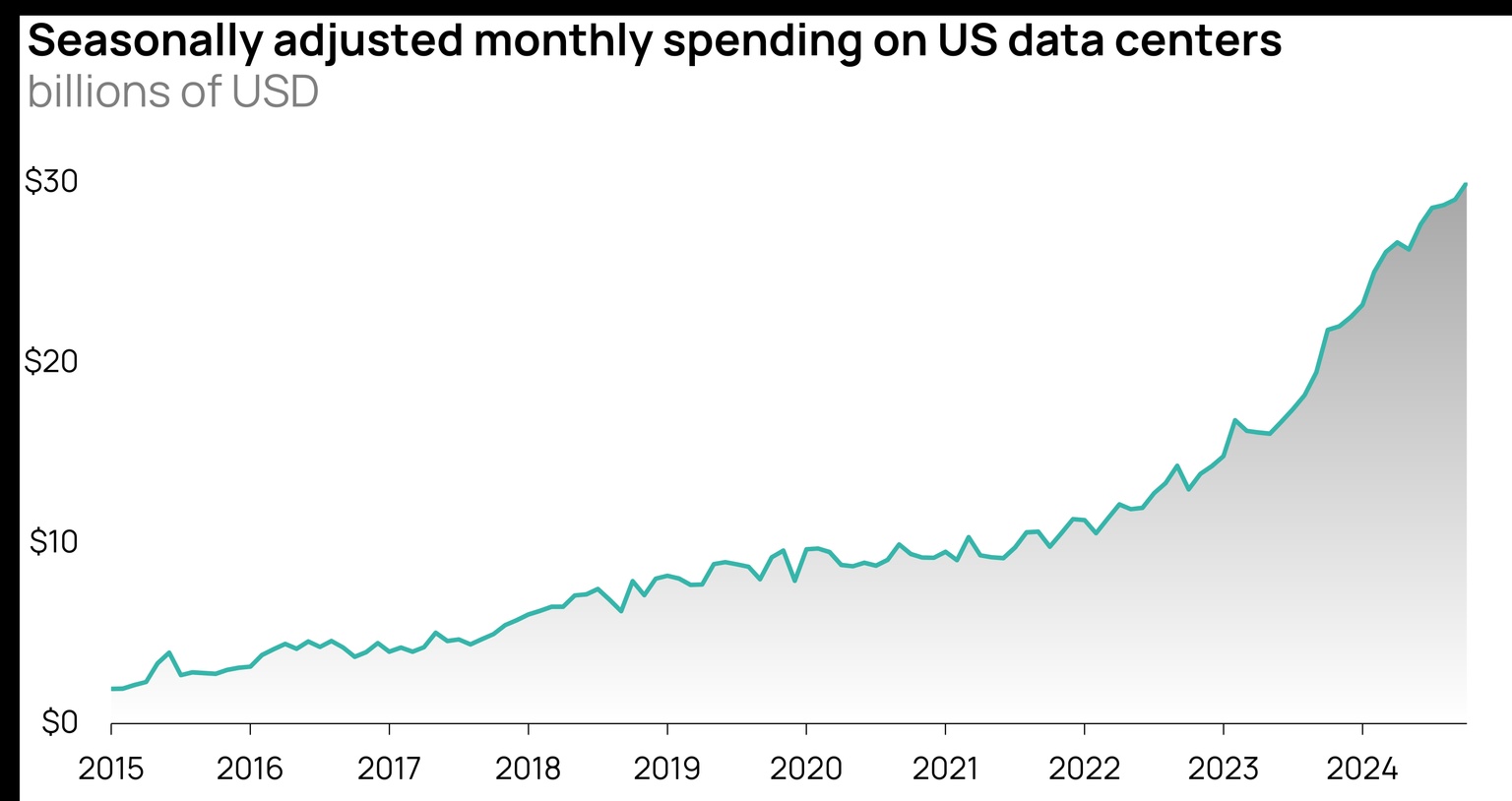
Source: US Census Bureau
Unlike the early British railroads, AI is not currently profitable and it’s not clear that an adequate return awaits the investors pouring capital into building data centers. Data is also a scarce resource. Companies will eventually run out of data to use in their models, and that day may not be too far off. Many view power as the factor that limits the scale and number of data centers. If there is a lack of available power for data centers or if communities increasingly push back against their development, the options on where to site the ever-larger facilities could be limited. And speaking of limited, it’s uncertain whether the labor pool for skilled trades, especially electricians, is deep enough to turn data center dreams into reality.
And if betting investors are any indication, there may be reason to be alert. Last year, record levels of money were put into the Invesco S&P Equal Weight exchange traded fund, which spreads its assets equally across S&P500 companies rather than weighted by their market value. This effectively shelters some exposure to BATMMAAN and underscores how investors are becoming wary of tech stocks.
Let’s dive in.
As Ray Dalio once said, he who lives by the crystal ball will eat shattered glass.
For investors to continue to pile capital into data centers and infrastructure, there needs to be some promise of a return that can be justified. If Bloomberg’s $1 trillion investment estimate is right, AI would have to be a historically transformative economic technology to justify that level of spending.
Cashing in: It should be said upfront, companies like Meta are already profiting from AI. Advanced machine learning is used extensively in the company’s advertising algorithms for platforms like Facebook and Instagram, but the profitability of the type of artificial intelligence known as generative AI has yet to be proven.
A key source of revenue for AI firms will likely have to be a huge number of users willing to pay to use AI-based tools, whether that’s companies or individuals.
Developers are hoping AI can be used by employees to improve performance or be incorporated into products. But according to the US Census, just 5.4% of American companies are actively using AI.
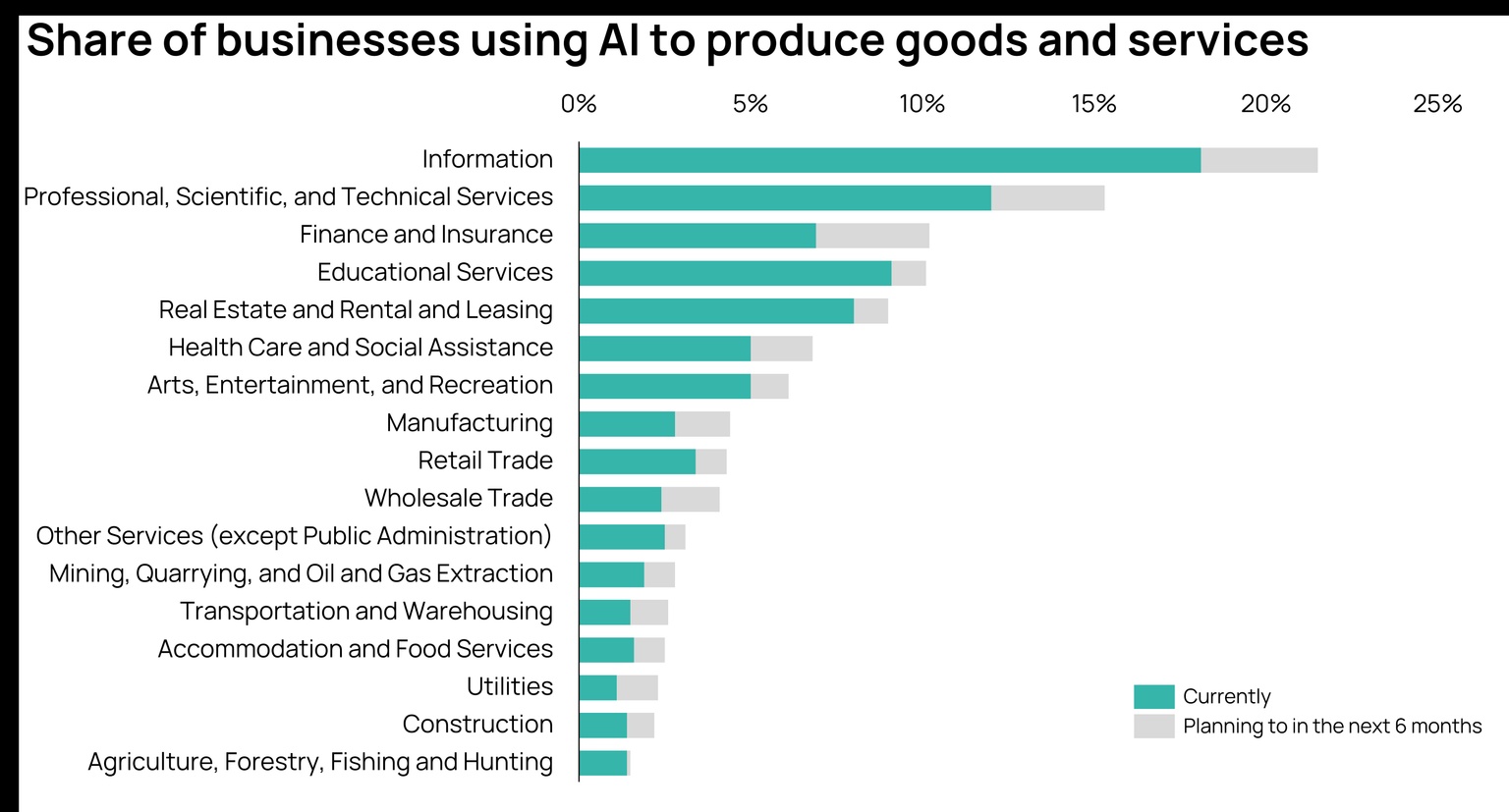
Source: US Census Bureau (March 2024 Business Trends and Outlook Survey)
In a paper published last year, MIT economics professor Daron Acemoglu argued we’re likely to see only a modest 0.5% gain in productivity and just a 1% increase in GDP due to the use of AI. Goldman Sachs’ head of Global Equity Research, Jim Covello, also points out that generative AI isn’t designed to solve the complex problems many tie to future economic growth related to AI.
Even many subscriptions are unprofitable today.
OpenAI is losing money: Sam Altman, CEO of ChatGPT developer OpenAI, admitted earlier this year on X (formerly Twitter) that the company’s subscriptions aren’t making money. “Insane thing: we are currently losing money on openai pro subscriptions! people use it much more than we expected,” wrote Altman.
While private, some financial details of the company have been seen by the tech bulletin The Information: OpenAI was set to spend $4 billion in 2024 just to use Microsoft servers — at a discounted rate — to run the ChatGPT workloads. With estimated revenues of $3.5 to $4.5 billion last year, its operating costs are roughly its revenues. Not ideal.
And, as pointed out by JP Morgan’s Micheal Cembalest in his latest Eye on the Market, the hyperscalers would need $400 to $500 billion in incremental annual revenues from AI to justify their $250 billion in yearly spending to keep tech margins where they are. Last year, they were closer to $100 billion.
There is hope that improved models in the future can better attract subscriptions and new revenues, but there are concerns the world is running out of data needed for those improved models.
At the heart of large language models (LLM) is data. Billions to trillions of individual data points, known as tokens, are used to train each model. Generally speaking, the more high-quality information fed into the model, the better its performance.
A primer: Tokens are units of data used for training models. For example, the text “I love cats!” contains five tokens: “I”, “love”, “cat”, “s” and “!”. There are also other modes of data other than text, including pictures. Every pixel in an image is an individual token, so your average 1024x768 resolution portrait of a cat contains nearly one million tokens for models to analyze. There are a lot of cat-related tokens out there.
Luckily, we’re a crafty bunch and have developed ways to chop up most of humanity’s digital existence into trillions of tokens to be used for training.
The data: It’s believed the largest known dataset used to train models today contains ~15 trillion tokens, and was used for Meta’s Llama 3 model. ChatGPT-4 used 13 trillion. As hardware, software and datasets improve, future models will incorporate even more, further improving the performance of models like Llama and ChatGPT.
Eventually though, we simply run out of data to put into the models.
Elon Musk, in a recent interview with Stagwell chairman Mark Penn, said that day may be fast approaching. “We’ve now exhausted basically the cumulative sum of human knowledge … That happened basically last year.”
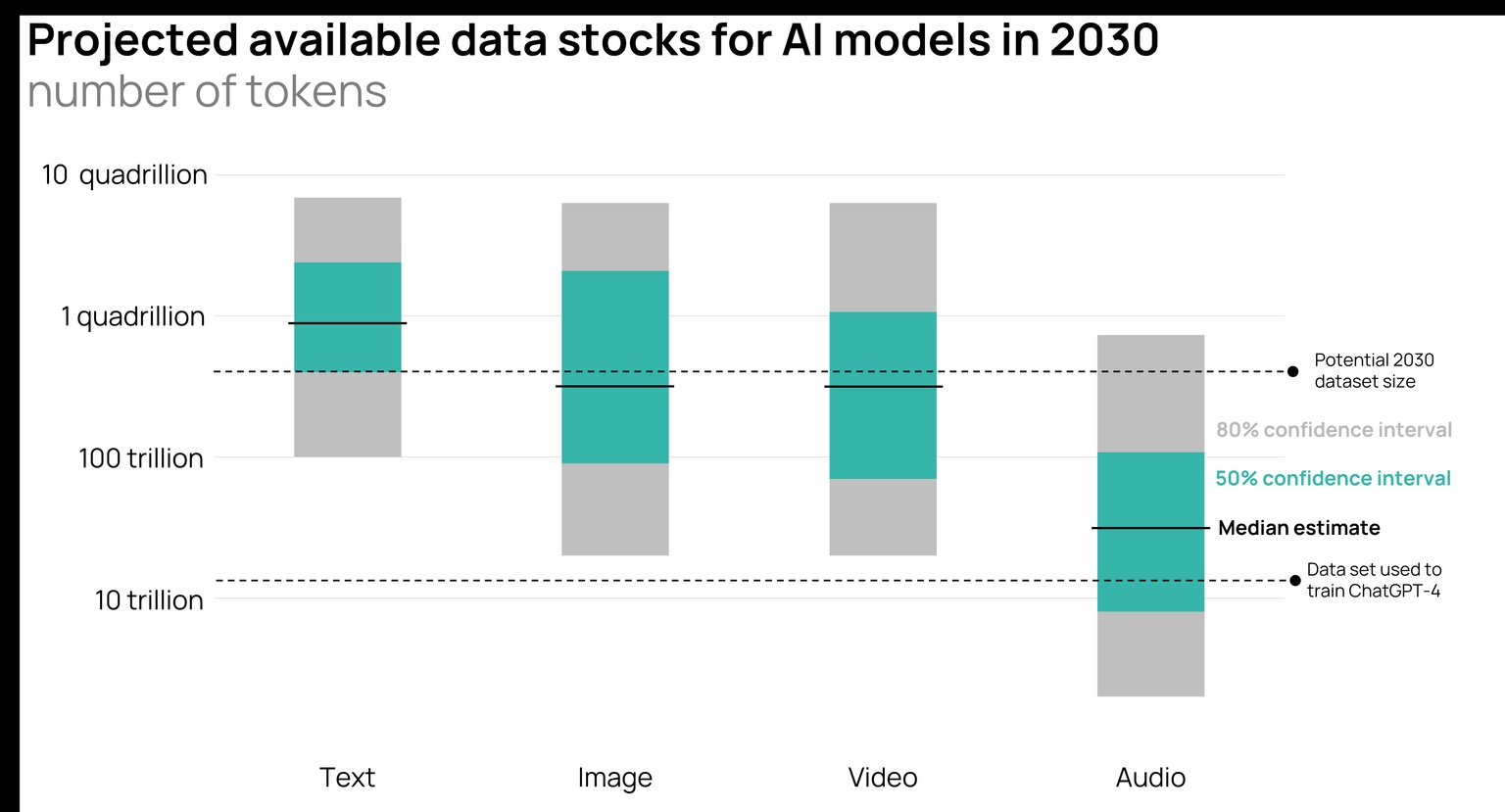
Data source: Jaime Sevilla et al. (2024), "Can AI Scaling Continue Through 2030?", Epoch AI
The AI research group Epoch AI put together a thoughtful piece last year on the limits of scaling AI. While the non-profit might disagree with the Technoking himself on timing, Epoch AI still found there could be real limitations on usable data for models that manifest by the end of the decade.
What it means: Training these incredible models on trillion-token-sized datasets is one of the main drivers for large data centers. If, as Musk put it, we exhaust the cumulative sum of human knowledge, the frantic demand for data centers could very well slow down.
Of course, to be able to feed a model all humanity’s knowledge, there need to be data centers large enough to handle those models and a commensurate supply of electricity to keep them churning.
Before jumping into the supply of power, it’s worth distinguishing between traditional data centers and AI-focused ones. Your traditional, non-AI data center typically acts as a house for individual computers — many independent or loosely interconnected servers working on separate tasks, like running email services or hosting cat videos. AI data centers are completely different.
With thousands of GPUs running simultaneously and cooperatively to train models, large-scale storage solutions to store intermediary results and a facility to ensure everything runs smoothly, the entire data center acts as one. AI data centers don’t house individual computers, they are the computers.
Size matters: The power and processing capacity of a data center limits how much data can be fed into models and ultimately the performance of the model being trained. A 200-megawatt data center running five times as long can’t accomplish what a one-gigawatt data center can because the former just can’t handle enough data all at once.
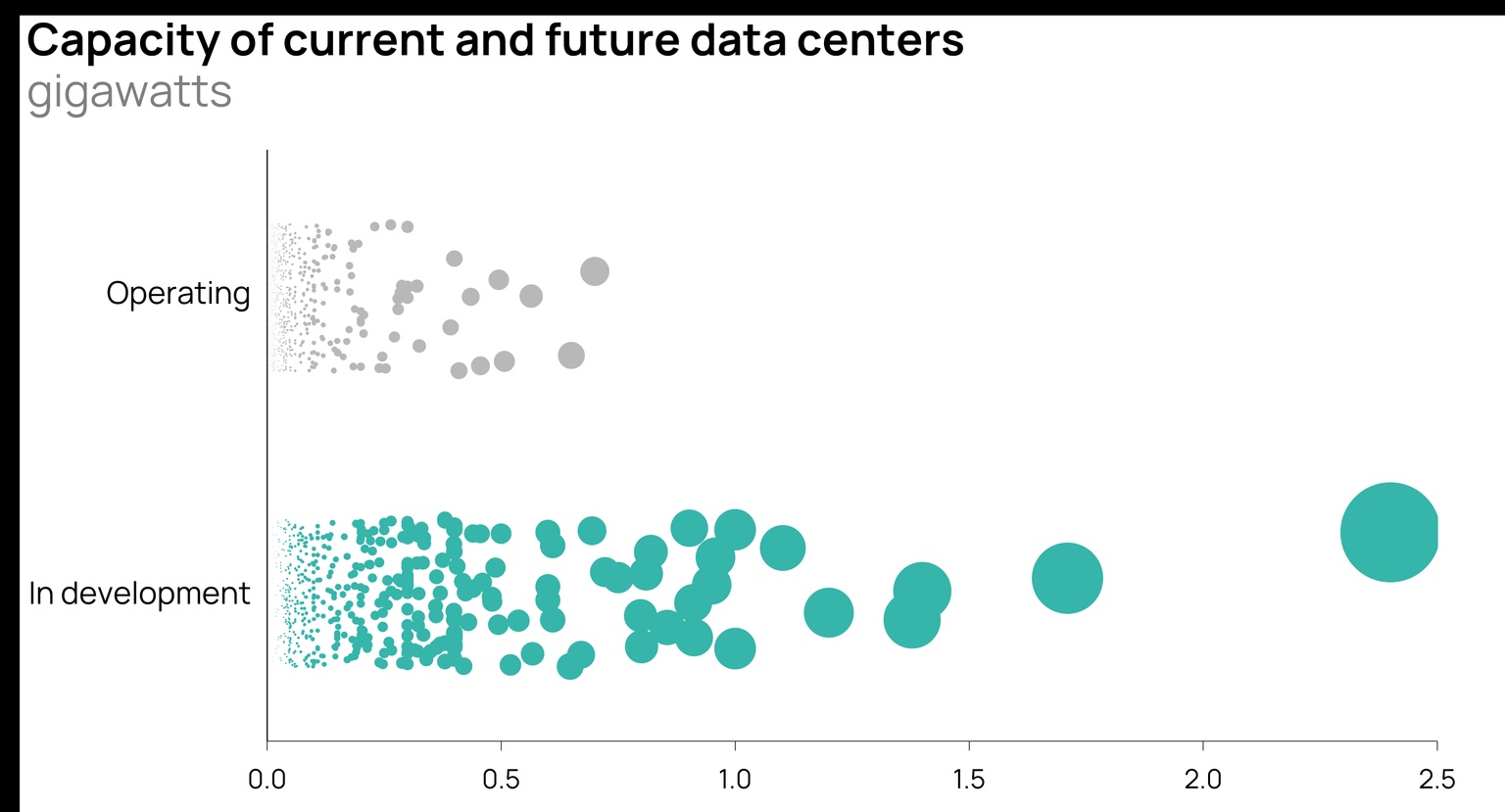
Source: Orennia
Epoch AI estimated how much more power LLMs will need for training by 2030. In its view, based on where models and datasets are going, frontier training runs will be 5,000 times larger than today’s largest models on the low end. Even with significant improvements in chip and software efficiencies plus longer training run times, Epoch views the power demands to train a single advanced LLM at six gigawatts (!) in 2030.
Put another way, if Epoch is right, five years from now, the leading models will be trained on data centers that consume electricity at a rate comparable to the largest power station in North America, the 7-gigawatt Grand Coulee Dam.
Hard to find that much power: The grid wasn’t designed with these sorts of large, focused power needs in mind. For several reasons, finding gigawatts of capacity available by 2030 will be no easy task.
For one, even smaller power plants today struggle with being curtailed. Building transmission lines continues to be a problem, yet without new infrastructure, large new loads like data centers will have existing curtailment issues and then some. And data centers may struggle to secure reliable power as building new generation remains time consuming and difficult. It takes an average of five years in most interconnection queues for a power project to secure an interconnection agreement.
The scale of power needed also presents other problems, notably whether data centers become harder to build.
Communities are increasingly skeptical of welcoming new data centers.
NIMBYism: Surging power demand from data centers has been a key driver behind higher electricity prices for residents in some states. In Oregon, increasing industrial energy demand, led by data centers, resulted in the electricity price for consumers climbing 40% since 2020, a trend familiar to other states that have welcomed the facilities. A report published by the Jack Kemp Foundation late last year estimates electricity bills could jump by as much as 70% from data centers.
This is leading some of the most active data center counties to working toward either bans or restrictions on their development, including Chandler in Arizona and both Fairfax and Loudon in Virigina.
Questionable upsides? Given the power needs and electricity price impacts from data centers, some communities are starting to question their benefit. There’s no doubt of the significant benefits for local suppliers and businesses during their construction; but once built, data centers employ few full-time staff.

Source: Tesla, eStruxture
And while their use should (and often does) bring in tax revenues to the local government, large tax breaks used to attract them often limit the gains for communities.
Lack of skilled labor: Data centers also face a skilled labor crunch, particularly for engineers and those with electrical expertise.
On a recent Veriten C.O.B. Tuesday podcast, Sean McGarvey, president of North America’s Building Trades Unions, highlighted the huge demand each data center has for skilled labor. “There is probably only five or six electrical contractors in the [US] that carry 1,000 electricians on their payroll. When you build a data center, in a lot of cases, you need 800 electricians,” McGarvey said.
And according to the US Bureau of Labor Statistics, employment of electricians will grow at nearly three times the rate of the average occupation between 2023 and 2033.
To be clear, it’s not certain data centers are in a bubble. There has been a lot of smart money put toward AI and data centers, up to $30 billion in the US last year alone, and it’s easy to see why. It took just two months for ChatGPT to reach 100 million active users, the fastest-growing consumer application in history. Revenue for the company grew 700% between 2022 and 2023. And the technology clearly represents a new front for national security, leading a US congressional commission to push for a Manhattan Project-style public initiative to ensure America leads the world in AI development.
So if even if it is a bubble, there are bubbles and there are bubbles.
Railway Mania’s impact: Britain’s economy in the mid-to-late 1800s didn’t stall out. Quite the opposite.
All that investment in rail laid the foundation for the country’s modern transportation infrastructure and created the backbone of the Industrial Revolution. Cheap transportation opened new markets for agriculture, reduced costs and even allowed citizens to enjoy cheap weekend excursions. Seaside resorts flourished.
While there was a period of pain for many shareholders of railways stocks, what dominates the history books was the period of great economic growth that followed and one of the great turning points in human history.
Bottom line: If the full magnitude of the data center frenzy doesn’t come to pass, there is no shortage of reasons why. But if history is prologue, then even modest spending on transformative technologies can still end up being societally transformed.
Insights for an evolving energy landscape delivered to your inbox.